CPU Cluster Romeo¶
Overview¶
The HPC system Romeo is a general purpose cluster based on AMD Rome CPUs. From 2019 till the end
of 2023, it was one part of a heterogeneous cluster, made available as partition romeo. With the
decommission of that former cluster,
Romeo has been re-engineered and is now a homogeneous, standalone cluster with its own
Slurm batch system and own login nodes.
Hardware Details¶
A brief overview of the hardware specification is documented on the page HPC Resources.
Processor
- 2 x AMD EPYC 7702 (64 cores) @ 2.00 GHz (Datasheet)
- Login nodes: 8 NUMA domains, 4 on each socket
- Compute nodes: 2 NUMA domains, one on each socket
System Memory
All Romeo nodes feature 512 GiB of RAM.
- 2 sockets with 8 memory channels each
- 1 x 32 GiB DDR4-3200 SECDED ECC-RDIMMs per channel, 16 DIMMs total (Part No. 18ASF4G72PDZ-3G2B2, product page)
- Theoretical peak bandwidth across both sockets: 409.6 GB/s
Local Storage
Romeo, similar to Alpha Centauri, has one 240 GB 2.5" SATA 6 Gb/s SSD (Samsung PM883,
Part No. MZ7LH240HAHQ-00005, product page,
datasheet of a closely related product)
per node, which is mounted at /tmp. Another 20 GiB partition is mounted at /var/tmp. Both
are formatted to xfs.
| Disk Type | Usable Capacity | Sequential read/write | Random read/write | Mountpoint |
|---|---|---|---|---|
| SATA SSD | 181.4 GiB | 550/320 MB/s | 98/14 kIOPS | /tmp |
| SATA SSD | 20.0 GiB | 550/320 MB/s | 98/14 kIOPS | /var/tmp |
See also: Node-Local Storage in Jobs
Networking
Romeo nodes feature one Mellanox ConnectX-6 InfiniBand device (user manual)
for networking. The network interface operates at 2xHDR (100 Gb/s, 12.5 GB/s).
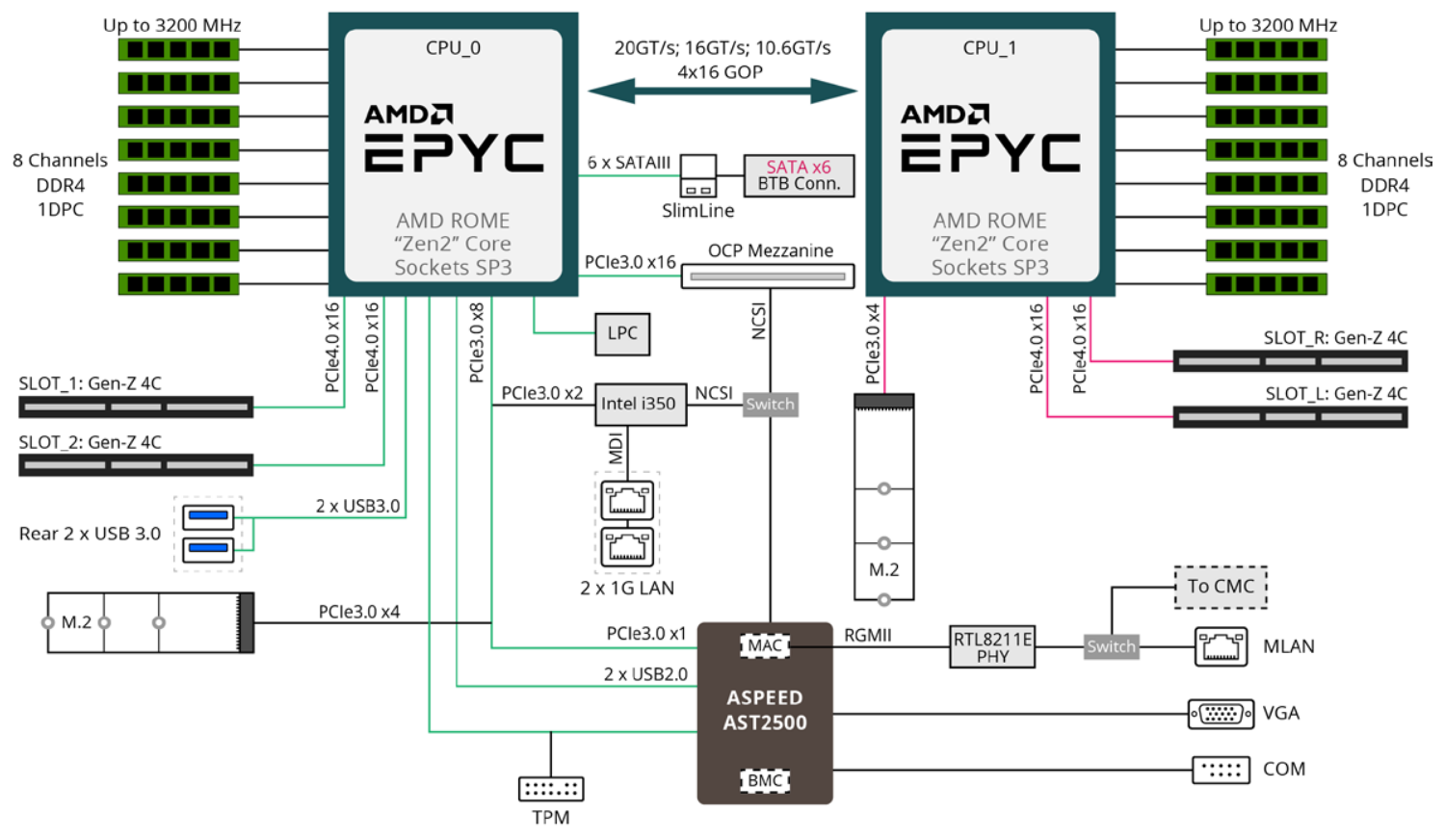
System Architecture
The system is based on Gigabyte H262-Z61-00 servers (product page, user guide).
System architecture:
Architecture output of hwloc-ls:

Operating System
Romeo runs Rocky Linux version 9.6.
Filesystems¶
Besides the regular working filesystems like horse,
Alpha Centauri's high IOPS filesystem quokka
is also mounted on Romeo. With this set up you can access your data produced by AI and ML
workflows on Alpha Centauri for pre- and post-processing on Romeo where no GPUs are required.
Unfortunately, this workflow cannot be automated in a pipeline with
job dependencies due to the
cluster configuration. Once your GPU jobs are completed, you would manually start the
post-processing on Romeo.
Usage¶
There is a total of 128 physical cores in each node. SMT is also active, so in total, 256 logical cores are available per node.
Note
Multithreading is disabled per default in a job. To make use of it include the Slurm parameter
--hint=multithread in your job script or command line, or set the environment variable
SLURM_HINT=multithread before job submission.
Each node brings 512 GB of main memory, so you can request roughly 1972 MB per logical core (using
--mem-per-cpu). Note that you will always get the memory for the logical core sibling too, even if
you do not intend to use SMT.
Note
If you are running a job here with only ONE process (maybe multiple cores), please explicitly
set the option -n 1!
Be aware that software built with Intel compilers and -x* optimization flags will not run on those
AMD processors! That's why most older modules built with Intel toolchains are not available on
partition romeo.
We provide the script ml_arch_avail that can be used to check if a certain module is available on
rome architecture.
Example, running CP2K on Rome¶
First, check what CP2K modules are available in general:
module spider CP2K or module avail CP2K.
You will see that there are several different CP2K versions avail, built with different toolchains. Now let's assume you have to decided you want to run CP2K version 6 at least, so to check if those modules are built for rome, use:
marie@login$ ml_arch_avail CP2K/6
CP2K/6.1-foss-2019a: haswell, rome
CP2K/6.1-foss-2019a-spglib: haswell, rome
CP2K/6.1-intel-2018a: sandy, haswell
CP2K/6.1-intel-2018a-spglib: haswell
There you will see that only the modules built with toolchain foss are available on architecture
rome, not the ones built with intel. So you can load, e.g. ml CP2K/6.1-foss-2019a.
Then, when writing your batch script, you have to specify the partition romeo. Also, if e.g. you
wanted to use an entire ROME node (no SMT) and fill it with MPI ranks, it could look like this:
#!/bin/bash
#SBATCH --partition=romeo
#SBATCH --ntasks-per-node=128
#SBATCH --nodes=1
#SBATCH --mem-per-cpu=1972
srun cp2k.popt input.inp
Using the Intel Toolchain on Rome¶
Currently, we have only newer toolchains starting at intel/2019b installed for the Rome nodes.
Even though they have AMD CPUs, you can still use the Intel compilers on there and they don't even
create bad-performing code. When using the Intel Math Kernel Library (MKL) up to version 2019,
though, you should set the following environment variable to make sure that AVX2 is used:
export MKL_DEBUG_CPU_TYPE=5
Without it, the MKL does a CPUID check and disables AVX2/FMA on non-Intel CPUs, leading to much worse performance.
Note
In version 2020 and above, Intel has removed this environment variable and added separate Zen codepaths
to the library. However, they are still incomplete and do not cover every BLAS function. Also, the
Intel AVX2 codepaths still seem to provide somewhat better performance, so a new workaround
would be to overwrite the mkl_serv_intel_cpu_true symbol with a custom function:
int mkl_serv_intel_cpu_true() {
return 1;
}
and preloading this in a library:
marie@login$ gcc -shared -fPIC -o libfakeintel.so fakeintel.c
marie@login$ export LD_PRELOAD=libfakeintel.so
As for compiler optimization flags, -xHOST does not seem to produce best-performing code in every
case on Rome. You might want to try -mavx2 -fma instead.
Intel MPI¶
We have seen only half the theoretical peak bandwidth via InfiniBand between two nodes, whereas
Open MPI got close to the peak bandwidth, so you might want to avoid using Intel MPI on partition
rome if your application heavily relies on MPI communication until this issue is resolved.
Backlinks¶
The following pages link to this page: